Accueil > Career > Como aprender Data Science do zero: por onde começar?
Como aprender Data Science do zero: por onde começar?
O que é Data Science? Como começar a aprender Data Science? Aqui você vai entender o processo completo da área de ciência de dados, o papel de cada profissional e como começar a aprender Data Science do zero para entrar nesse mercado e se profissionalizar!
Índice de conteúdo
Fique por dentro das últimas tendências de tecnologia e novidades sobre IA com a newsletter da Le Wagon.
Você quer aprender Data Science mas não sabe exatamente por onde começar? Me acompanha até o final desse post que a gente vai te ensinar o caminho das pedras
Ao longo do texto eu vou te explicar mais sobre a diferença entre o engenheiro de dados, analista de dados e cientista de dados, mostrar os motivos pelos quais, toda empresa, vai precisar de um setor de Data Science no futuro
Além disso, você vai aprender as melhores maneiras de como aprender Data Science e outras sub-áreas importantes desse amplo campo do conhecimento, como Decision Science, Machine Learning e mais!
Bóra juntos nessa aventura? Então vem comigo!
Afinal, o que é um Data Scientist?
Existem diferentes cargos na área de análise de dados, os principais são engenheiro de dados, analista de dados e cientista de dados.
Ainda não tá clara a diferenças entre eles na prática? Saca só:
Engenheiro de Dados ⚙ ♀️
Entre as principais atividades que esse profissional executa, está a coleta de dados e o tratamento das informações e limpeza de dados.
Cada interação de um usuário gera um novo pixel de informação e as empresas entenderam a importância de analisar o máximo de dados possíveis, para obter vantagem competitiva, afinal de contas, conhecimento é poder. Hoje vivemos na Era da Informação e gerados enormes volumes de dados diariamente, e assim, foi cunhado o conceito de Big Data.
Big Data
Big Data nada mais é que o processamento, limpeza, tratamento, e análise de grandes quantidades de dados e grandes variedades de dados, com a utilização de poder computacional.
É dito que o Big Data tem 5 V's:
Volume
Variedade
Velocidade
Veracidade
Valor
O ponto ao redor do Big Data é ter mais informações e ter informações mais rapidamente, como uma vantagem competitiva de negócio.
Essa é a responsabilidade do engenheiro de dados, garimpar as informações necessárias para que elas sejam tratadas e permitir que as análises de dados sejam mais claras.
Ele faz isso por meio do ETL (Extract , Transform and Load), também conhecido como ETC (Extrair, Transformar, Carregar) em português.
Imagine que um cliente passe um banco de dados com as informações de um grupo de clientes específicos de seu e-commerce.
Neste banco de dados podem existir informações faltantes, podem haver valores de dados armazenados que não fazem sentido, como por exemplo: "-99, -999, ?, #$%@" .
O papel do engenheiro de dados, vai variar de acordo com a empresa e seu nível de maturidade em Ciência de Dados, mas normalmente o engenheiro de dados, fica responsável pelos processos de ETL.
Extract
O Engenheiro de Dados pode extrair seus dados de diversas fontes diferentes, algumas das principais delas são:
Bancos de Dados (SQL ou NoSQL)
Web Scraping
APIs
Transform
Aqui o engenheiro de dados deve limpar o dataset através de práticas como enconding, adicionando valores faltantes através de métodos de input ou também retirando dados em branco, dados não-relevantes para as análises e substituindo valores que foram armazenados de forma incorreta para deixar o banco otimizado para a análise poder ser bem feita, e serem carregados em ferramentas de visualização.
Ou seja, no banco de dados recebidos a primeira etapa será de extração das informações onde o engenheiro de dados fará a comunicação daqueles informações com outros sistemas a fim de capturar os dados que devem ser inseridos. Muitas vezes seu papel pode ser automatizar a comunicação de dados entre dois sistemas diferentes.
Load ⏩
Por fim, uma vez com os dados limpos e tratados, ele deve prepará-los para a etapa de carregamento, onde profissional deve ajustar as ferramentas de visualização para que o analista ou outros profissionais de Data Science possam cruzar os dados e realizar suas respectivas análises
O engenheiro de dados deixa tudo automatizado para que haja o mínimo de interferência humana e o próprio sistema tenha a capacidade de entregar a informação certa. Uma boa prática de carregamento de dados automatizados é o Data Streaming, onde a visualização de dados, já pré-configurada para determinadas análises, é carregada em tempo-real e atualizada a todo momento, no período de tempo escolhido.
Analista de Dados
Depois que o engenheiro cuida dos dados por meio do ETL, o analista já receberá essas informações tratadas e deve se preocupar em cruzar os dados, analisá-los, construir gráficos e pranchetas de visualização das informações como foco no auxílio da tomada de decisão tendo uma visão de negócio.
Ou seja, ele precisa entender o que os dados querem dizer no contexto prático da coisa. Ele recebe o conjunto de dados prontinho para ser analisado, e é importante o Analista ter o conhecimento de negócio e de mercado, para se fazer as perguntas certas, do que deve ser descoberto. Aqui é importante usar a metodologia científica e realizar a formulação de hipóteses do que se deseja desvendar.
Este profissional deve construir uma interface onde essas informações possam ser vistas e acessadas facilmente. O Analista de Dados ou Analista de Negócio tem a função de dar contexto aos dados e entender o que eles significam na realidade da empresa, para otimizar seus processos, produtos, melhorando eficiência, e eventualmente com objetivos também de negócio, como aumento de receita ou de lucro.
Cientista de Dados
Já o Data Scientist deve ter a capacidade de entender isso tudo e um pouco mais. Por mais que o Cientista de Dados, não precisa saber executar todas essas etapas prévias, é importante que ele entenda o contexto geral do fluxo de dados dentro da empresa e ter a visão do "macro", ou do todo.
Se o analista de dados está para o passado, o Cientista de Dados está para o futuro. Seu foco é fazer previsões baseado em modelos matemáticos robustos e estatística, encontrando padrões entre os dados e utilizando de tecnologias como aprendizagem de máquina.
Uma das possibilidades aqui, e dada como uma das mais glamurosas dentro de ciência de dados é a criação e aperfeiçoamento de algoritmos que automatizam tomadas de decisões do negócio.
Um grande exemplo é o algoritmo de recomendação de filmes na Netflix, que utiliza de tecnologias de agrupamento ou data clustering mas compreender como um conjunto de dados se divide em sub-grupos de comportamento ou preferências por gostos cinematográficos e encontra usuários com gostos e comportamentos semelhantes dentro da plataforma, cruzando os dados, de filmes que você e um usuário em comum com você assistiram, e te recomenda algum filme que você não viu e que seu "clone" não assistiu ainda e vice-versa.
O mesmo funciona para Spotify, Tinder e praticamente todas as grandes plataformas de tecnologia utilizam dessas tecnologias, mas de diferentes formas e com diferentes objetivos.
Um Cientista de Dados precisa lidar com gigantescos volumes de dados em tempo real, com isso vem a necessidade de criar mecanismos que suportem essa concentração de informações e ao mesmo tempo faça o tratamento e apresentação dos mesmos.
Por que empresas precisam de Data Scientists? Data is the new Oil ️
As empresas modernas são cada vez mais digitais. Como já disse, no mundo virtual, cada ação que fazemos gera uma nova informação.
Agora imagine uma loja virtual no porte do Magazine Luiza que deve receber milhares de visitas e compras mensais. Imagine que cada clique, cada rolagem de página e até o tempo que você permanece em cada seção é um dado diferente.
Todos nós geramos um volume de dados muito grande. Esses dados podem ser divididos entre dados estruturados e não-estruturados:
Dados estruturados
São aqueles que possuem um padrão pré definido. Utilizam uma estrutura bem rígida e geralmente são criados antes do surgimento das informações.
Eles geralmente são criados em ferramentas de tecnologia analíticas como o excel, por exemplo.
Essa estrutura é bem definida pois, se você cria a regra de que um campo deve aceitar apenas números, não será possível adicionar uma vírgula ou uma letra.
Um exemplo de dados estruturados são dados armazenados em SQL, ou Structured Query Language, que nada mais são que tabelas de chave-valor, como as planilhas de excel, mas dessa vez, em um banco de dados dinâmico, como o MySQL ou Postgres. Para cada chave existe um valor. Assim como um jogo de Batalha Naval!
Dados não-estruturados
Diferente dos dados estruturados, os não estruturados não seguem padrões rígidos, sendo bem flexíveis e dinâmicos.
Esse tipo de informação é uma das mais produzidas no mundo virtual justamente por sua facilidade de mudança e aceite de diferentes caracteres.
Um exemplo disso são os dados gerados nas redes sociais. Diante de tanta informação que é produzida a cada segundo por meio da publicação de fotos, vídeos e textos, limita-las numa estrutura fixa não seria eficaz.
Um exemplo de dados não-estruturados são todos os tweets gerados diariamente, que são informações não organizadas, mas que podem conter um valor importante para compreender cenários. Neste caso, por exemplo uma prática realizada por empresas, como o monitoramento de redes sociais, servem para fazer análise de sentimentos dos usuários com base no que é dito por cada um.
Assim o papel de um Data Scientist se faz cada vez mais importante e não é atoa que a demanda por esse profissional cresceu tanto nos últimos anos.
As empresas perceberam que dados podem ser convertidos em informação, quem tem informação, tem poder e quem tem poder tem vantagem competitiva no mercado.
Por isso, uma pessoa que deseja aprender Data Science tem uma grande oportunidade de carreira. Entre as principais formas de como os profissionais contribuem para o crescimento das instituições é possível citar:
Otimização para Tomada de Decisões
Os dados não mentem. As empresas estão construindo cada vez mais uma cultura orientada por dados, ou data-driven, e junto com isso, vemos cada vez mais a utilização de estatística, matemática e metodologia ciêntífica na análise de dados para tomar decisões, principalmente em empresas de tecnologia, que têm mais dados disponíveis para serem analisados, infra-estrutura e tecnologia para viabilizar essas análises e a capacidade de tranquear estes dados, devido aos seus produtos e modelo de negócio.
Observando essas ações os Cientistas de Dados são capazes de construir hipóteses e validações bem embasados que influenciam o caminho no qual o negócio irá seguir, tanto num nível tático quanto estratégico. É por isso que Data Science é um setor estratégico, próximo de um nível alto de hierarquia na companhia, e sempre bem acompanhado de demandas de Diretores e os C-levels da empresa.
Otimização de Processos
Imagine que uma empresa de logística, que possui uma frota de caminhões gigante e também centenas de pedidos para serem entregues todos os dias. Traçar as rotas manualmente e estimar o tempo gasto nas entregas seria algo impensável de se fazer.
Data Science pode otimizar os processos de logística, tornando-os mais eficientes, o que pode significar economia de tempo e dinheiro. Nesse exemplo, um Cientista de Dados pode construir um algoritmo capaz de coletar dados fornecidos por um GPS (como informações meteorológicas, situação do trânsito em tempo real e até mesmo tipos de estrada se é asfaltada ou não) para prever as melhores rotas e estimar o tempo de entrega de cada produto. Além disso, pode também, realizar análises de demanda, entrada e saída de estoque para prever em quanto tempo irá falta determinado produto, e quando e em qual quantidade deve comprá-lo.
Assim, por meio dessas informações, as empresas podem maximizar as operações no setor, passar uma previsão de entrega mais assertiva para o comprador, diminuir os desgastes na frota de caminhões e com isso, reduzir os gastos com imprevistos que possam ocorrer.
Indo além, um Cientista de Dados pode aplicar os conceitos de Machine Learning (aprendizado de máquina) para que o algoritmo aprenda os melhores caminhos a se fazer, trabalhando de forma automática.
Otimização de Produtos: Usando feedback de comportamento dos usuários
Você já deve saber que, ao construir uma empresa, você não pode criar uma solução para você e sim para o seu público, resolvendo alguma dor de mercado, comprovada pela reafirmação de demanda pelo seu produto ou serviço.
É dito que produtos digitais, nunca estão prontos, ou terminados. Isso é dito, por que os produtos precisam ser atualizados, e essa atualização, é feita com base na análise de comportamentos dos usuários, para gradativamente, adaptarmos o produto digital, otimizando a experiência do usuário e compreender o que é de maior valor para os cleintes. Através das ações individuais de cada um é possível identificar padrões de comportamento e com isso melhorar o produto. Um bom exemplo, é só você pensar em quantas vezes o Facebook, Instagram, Netflix, ou qualquer outro software que você usa no dia-a-dia foi atualizado ou mudou de interface nos últimos tempos.
O feedback dos usuários precisa ser coletado de diferentes maneiras e um bom cientista de dados, consegue sumarizar esses dados e rastros de pixels deixados por eles para melhorar seu produto, e consequentemente seu negócio.
Esse é um dos motivos pelos quais a demanda por Cientistas de Dados tem crescido cada vez mais, não só em grandes empresas de tecnologia, mas também small business e mid market também. A Era é da informação, e com muita informação e muitos dados, todo mundo vai precisar de um cientista de dados, para tomar decisões de negócio, cada vez mais orientada por dados. É por essas e outras que o cargo de Cientista de Dados é o com maior crescente em todo mundo de acordo com este report sobre o Futuro do Trabalho do World Economic Forum.
A demanda por esses profissionais não acompanha com aumento de oferta, e o ticket desse profissional está se tornando um dos mais caros do mercado, justamente pela falta de especialistas e formação na área.
Aprenda a programar
Quem deseja aprender Data Science deve saber que para se tornar um profissional cobiçado no mercado é necessário ter uma base sólida em:
Matemática: álgebra linear, função polinomial do 1º e 2° grau, trigonometria, função logarítmica, etc.
Estatística: probabilidade, inferência estatística, regressão linear, tipos de variáveis, amostra, tipos de gráficos, etc.
Programação e Desenvolvimento: Aqui as linguagens mais famosas são R e Python.
Um Cientista de Dados precisa ter uma base sólida em programação e em matemática/estatística, para ser capaz de compreender o que acontece "por detrás do capô" dos algoritmos e bibliotecas utilizadas e populares entre esses profissionais. Sem isso é como um mecânico que pode até mesmo saber como consertar o carro e resolver o problema do "sintoma" mas nunca saberia o por quê do carro ter estragado em primeiro lugar, ou seja, não saberá o diagnóstico completo.
Não entendeu ainda? Vamos lá:
Um exemplo de um job de Data Science seria por exemplo o seguinte.
Você está tomando seu café da manhã, trabalhando de home office, quando de repente, você recebe um e-mail do seu CFO, João Paulo Aranha, pedindo para seu time realizar uma análise preditiva para calcular em quantos por cento aumentaríamos a taxa de cancelamento mensal da Revista AquiloÉ se aumentássemos em 1,58% o preço da mensalidade. Cientistas de Dados devem juntar as bases de dados, para primeiro compreender as modalidades de assinatura dos clientes, logo os padrões dos históricos de cancelamentos dos leitores e assim, realizar uma projeção preditiva do aumento da taxa de cancelamento, em relação à sensibilidade do preço e a disposição a pagar das pessoas.
Para isso, será necessário usar bibliotecas de Machine Learning como scikit-learn, para realizar análises de regressão linear e regressão logística, entre outras análises e construir um modelo preditivo de Machine Learning para avaliar esse resultado e encontrar um ponto ótimo, onde talvez, se aumentássemos em 1,58% o preço da assinatura, provavelmente o total da receita de perda de novos clientes que não têm disposição a pagar o novo preço incrementado, em detrimento do aumento do faturamento em resposta aos clientes que permanecessem. E assim, encontrar um ponto ótimo, onde talvez, 1,58% seja um aumento substancial, e não deve-se tomar essa decisão de negócio. Tampouco, não aumentar em nada o preço da revista, pode ser prejudicial, mas talvez se aumentássemos em 0,97%, as somas dos outcomes positivos com negativos, pudesse resultar em um jogo de soma-positiva.
Sem o poder computacional para otimizar a eficiência das análises, tudo teria que ser feito como os matemáticos e estatísticos faziam antigamente: Na mão. Isso não é impossível, mas é bastante trabalhoso… Por isso com as novas tecnologias disponíveis, e com a imensidade de dados a serem analisados, se você quer se tornar um cientista de dados, você precisa aprender a programar.
Legal Vítor, mas e agora? Como eu posso começar a entender mais sobre essa área de Data Science para saber se isso é pra mim mesmo ou não?
Você começar a aprender mais sobre data science aqui.
Ciência de Dados é um campo extremamente amplo, onde dá para se especializar muito em pequenas sub-áreas, mas o "feijão com arroz" mesmo começa aqui:
Aprenda a programar em Python
A linguagem de programação Python é uma linguagem de alto nível, com tipagem dinâmica e tem diversas bibliotecas disponíveis que permitem agilizar o trabalho do cientista de dados.
A linguagem de programação junto às bibliotecas permitem analisar arrays e matrizes multi-dimensionais facilmente, estruturas e operações de dados e ainda trabalhar com tabelas numéricas complexas.
Com Python você pode trabalhar analisando quaisquer fontes de informações, bancos de dados estruturados e não estruturados, web-scraping, xmls files ou cvs ou até mesmo APIs.
Quer ver como aprender Python? Leia nosso guia completo com todas as informações necessárias que você precisa para desenvolver seus conhecimentos nessa linguagem.
Bibliotecas Pandas e Numpy
As Libraries Pandas e Numpy permitem acessar os grandes bancos de dados (SQL) e junto com o Kaggle.com você terá os dados necessários para brincar com novos projetos.
No Kaggle você poderá acessar mais de 50 mil banco de dados públicos e mais de 400 mil notebooks públicos para trabalhar a análise de dados e explorar diferentes áreas no campo da ciência de dados.
Além disso, você pode participar de competições. Elas têm o objetivo de desafiar os participantes na resolução de problemas reais de grandes empresas. Ou seja, você tem a possibilidade de colocar seu conhecimento no mercado em tempo real.
No fim de cada competição o ganhador pode levar um prêmio em dinheiro.
Para terminar as análises de dados você pode utilizar o Google Collab ou Jupyter Notebook. Ambas são ferramentas online dedicadas, entre outras coisas, à análise de dados.
Linguagem R
A linguagem R também é muito utilizada é necessária se você quer aprender data science. Ela permite a construção de um ambiente ideal para construção de gráficos e fazer estatísticas como:
Modelagem linear e não-linear;
Testes estatísticos clássicos;
Análise de séries temporais;
Classificação;
Agrupamento.
Domine Visualização de Dados ou Dataviz
Enquanto as bibliotecas e ferramentas citadas acima permitem você aprender Data Science, existem outras que vão te ajudar a visualizar os dados de maneira mais intuitiva e agrupada.
Muitas pessoas utilizam o BI ou Tableau para fazer suas primeiras visualizações, no entanto essas ferramentas foram criadas para o analista de dados e não para o cientista.
Porém existem outras formas de se fazer isso, inclusive existem 2 bibliotecas para Python famosas nessa área: matplotlib e seaborn.
Enquanto o matplotlib abrange a criação e visualização de dados de uma maneira animada e interativa, a biblioteca Seaborn permite a construção de gráficos atraentes e muito informativos.
Dedique-se a aprender mais sobre elas e explique suas possibilidades.
O que é Decision Science? ✖➕➖➗
A união entre matemática e dados só poderia resultar em tomadas de decisões com muito mais probabilidade de acerto.
Ou seja, o cientista de dados deve utilizar recursos matemáticos apoiados por ferramentas computacionais para criação de diferentes cenários possíveis a fim de justificar uma determinada decisão de negócio e mostrar o que pode acontecer se seguir outras direções.
Decision Science é onde unimos a estatística, a análise de dados com programação e poder computacional, com as métricas chave do negócio, como por exemplo, OKRs e KPIs. Esses conhecimentos, permitem entender a relação entre os dados e variáveis do negócio, para através de engenharia de dados, encontrar novas variáveis e parâmetros, que vão ajudar a compreender melhor a realidade e a tomada de decisões orientada por dados, invés de uma tomada de decisão, orientada por f eelingou achismos.
Em Decision Science, usa-se muito de métricas comuns da estatística, como média, mediana, desvio padrão R² e graus de correlação, regressão linear e regressão logística para desvendar como os indicadores se relacionam e obter insights de negócio.
Dessa forma, as empresas que usam esse recurso saem na frente da concorrência, já que não tomam decisões baseadas em achismos.
A Ciência dos Dados
Em Data Science, diferente de qualquer outra análise de dados normal, segue rigorosamente e metodologia científica da academia para processualizar suas análises. É justamente o rigor científico a utilização desse método unidos à matemática, estatística e programação, que batizaram o nome desse profissional.
Com o método científico, as empresas se blindam de realizar análises enviesadas, que não compreendem a realidade, e sair da caixa para ampliar a granularidade dos dados, e obter análises mais assertivas.
O método científico:
Observação: Assim como Galileu Galilei, o pai da ciência moderna, utilizou da observação e experimentação para analisar um fenômeno, aqui Data Scientist escolhem seu objeto de análise
Elaboração do Problema: Aqui, antes de determinar quais respostas se querem encontrar, é importante antes você se fazer qual pergunta, ou qual problema você quer responder ou resolver. Uma boa pergunta pede uma boa resposta.
Elaboração de Hipóteses: Com base na observação do objeto de estudo e com base nas perguntas elaboradas, tenta-se estipular possíveis respostas para o problema.
Validação: Aqui para os Cientistas de Dados, é aonde inicia-se as análises de dados e tudo que vimos até agora para validar se alguma das hipóteses estipuladas de fato responde a pergunta do problema ou não, com vazão para serem validadas ou invalidadas.
Análise de Resultados: Após a escolha da metodologia de análise, e após rodadas todas as devidas análises de dados, com as visualizações disponíveis, discutimos e assinalamos as conclusões obtidas dos experimentos.
Conclusões
Aprenda Machine Learning
Não existe Cientista de Dados "unicórnio". Aquele que sabe fazer de TUDO. O Data Scientist peer-to-peer. O Rodrigo Hilbert da Ciência de Dados. Não. Isso é lenda urbana e folclore, assim como Saci Pererê, Mula-sem-cabeça e o Curupira...
Em grandes empresas, ou as big tech companies, como Apple, Microsoft, Facebook, Amazon e por aí segue a lista dos residentes de Palo Alto, do Silicon Valey... Enfim, todos esses têm times inteiros de Data Scientists, segmentados, onde cada um tem determinada especialidade e responsabilidade por uma pequena parte de todo esse processo. Até mesmo um Gestor ou Líder de área, por mais que seja importante compreender todo o processo, desde a extração, processamento até o deploy, ele não vai saber executar na íntegra todas as etapas...
Machine Learning, sem dúvida é uma das habilidades mais populares hoje em dia, muito em alta, mas na verdade são poucas as pessoas que realmente compreendem do que se trata e como acontece esse processo. Com certeza é aonde a maioria dos Cientistas de Dados gostaria de estar trabalhando aqui, mas pouca gente sabe, mas a parte de modelagem, é a cereja da cereja do bolo. 95% à 99% do tempo você fica na parte de ETL, limpando os dados, e só, somente só, quando está tudo prontinho para ser analisado que entra a parte "legal" de ML. sabe de nada inocente! rsrsrs
E lembrem-se: Machine Learning é uma técnica que nem sempre precisa ser usada! Muita gente se perde pela vontade de usar ML quando muitas vezes não tem a menor necessidade, e uma simples regressão linear dá conta de resolver o problema. Não tenham medo de não usar ML.
Machine Learning é um bem diferente de análise de dados. Enquanto na análise de dados você tem um input, dos dados a serem analisados e tem um output, que são as análises de fato. Em ML você já começa com o input e o output juntos. Mas como assim Vítor?
Vamos lá, é mais simples do que parece: Existem dois tipos de Aprendizagem de Máquina:
Supervisionada
Não-Supervisionada
Daqui a pouquinho voltamos aqui. Segura aí! Em Machine Learning, você já começa com um dataset com o input, e com o output, no sentido de que, você já tem as análises de determinados resultados de alguns comportamentos dentro da sua base de dados, e aqui, o objetivo é criar um modelo ou algoritmo, que com base nos padrões de input e de output, seja capaz de prever sozinho, através do aprendizado ao interagir com um novo dados nunca antes visto pelo modelo, qual será a classificação ou output dele, com base no seu treino com o dataset inicial. Capicci?
Você pega seu dataset, divide ele da melhor forma possível (também com boas práticas e com base em algumas fórmulas e bibliotecas de ML) e dai você separa ele em duas partes:
Treino
Teste
O treino será a maior parte do seu dataset (70% via de regra) para treinar seu modelo e alimentar o algoritmo a entender e analisar os padrões de input x ouput. Aí sim, uma vez treinado e instanciado o modelo de ML, voce pegará o resto do seu dataset, os outros 30%, nunca antes interagido com o modelo e analisar em quantos por cento, ele irá ser capaz de acertar o output dos dados, sejam eles uma classificação (Frio ou Quente, True or False, A ou B ou C ou D) ou seja ele algum resultado específico (X, Y, Z, R²).
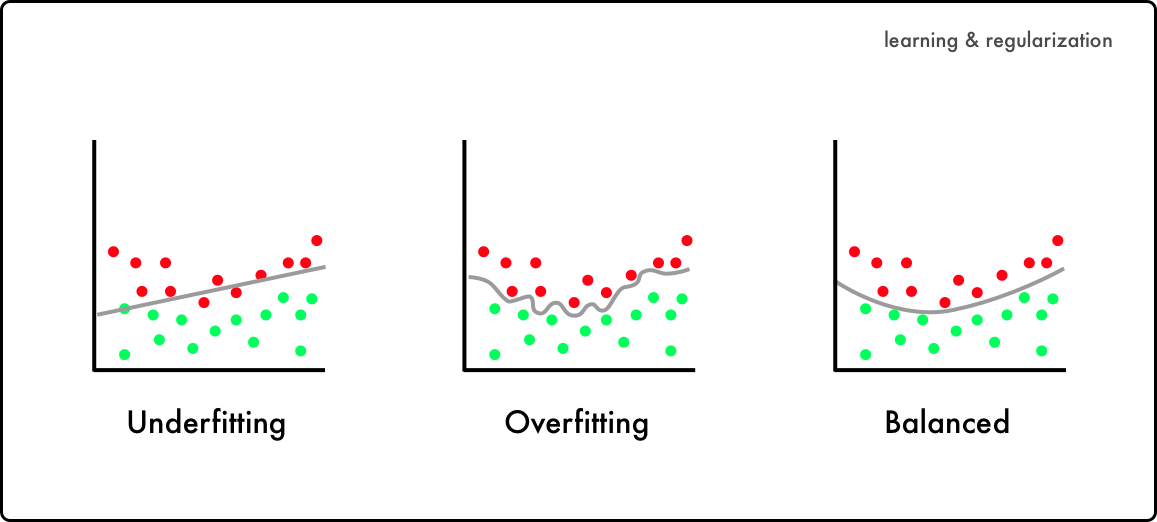
Cuidado com seu modelo, pois você pode ter resultados bem enviesados. São chamados eles de Overfitting e Underfitting. Underfitting, Overfitting & Balanced Underfitting
Nesse caso, o modelo já é ruim desde na própria etapa de treinamento. Ou seja, o recorte da divisão do dataset entre treinamento e teste foi mal feita, de modo que a amostragem de treino, não tem uma representatividade do que acontece de fato na realidade do conjunto inteiro.
Sendo assim, o algoritmo, não consegue entender corretamente como os dados se relacionam e você deve corrigir isso, re-instanciando novamente o modelo, até encontrar uma boa divisão do recorte entre os dados para alimentar o treino e os dados para testá-lo.
Overfitting
O Overfitting, é quando seu modelo Aprendizado de Máquina é tão assertivo, que não houve aprendizagem do algoritmo, e que ele na verdade, decorou os outcomes com base no dataset.
Aqui o modelo atua de forma que se inputado novamente com um dado equivalente à algum já antes visto, ao invés de processar um novo resultado de outcome, dá a correspondência exata daquele datapoint, como se fossem atributos de chave-valor. Quando isso acontece, o modelo é ineficaz para prever novos resultados.
Balanced
Um bom modelo de Machine Learning, é aquele cujo recorte do dataset entre treino e teste foi bem feito e representativo, de modo que a acurácia do modelo de ML seja alta para prever novos resultados quando interagir com novos pontos de dados. Normalmente um bom modelo de ML fica entre 95% - 99% de acurácia, mas também vai depender de N fatores das especificidades do que você está analisando.
E para que serve Machine Learning?
Você já pensou como a Netflix faz sugestões de séries tão próximas daquilo que você pode gostar ou como os carros autônomos conseguem dirigir sozinhos pelas cidades? Respectivamente com técnicas de data clustering, ou agrupamento de dados na Netflix, e NLP, ou Natural Language Processing, o processamento de textos, imagens e vídeos, no caso dos carros auto-dirigíveis, da Tesla.
No caso da Netflix, seus algoritmos compreende os gêneros que você assiste frequentemente, o que você pesquisa na plataforma, quanto tempo você passa assistindo e mais uma série de informações para te recomendar séries e filmes que você terá mais probabilidade de assistir. Também faz recomendações com base em usuários com gostos por filmes e séries similares aos seus.
Tudo isso é possível com o Machine Learning. A partir dos seus comandos um computador conseguirá tomar decisões sozinhos baseados no que ele vai aprendendo ao longo do tempo.
O que é Deep Learning?
O deep learning é uma sub-área dentro de Machine Learning, que tem o objetivo de ensinar os computadores a realizarem tarefas como um ser humano faria. Tá mas qual a diferença, Vítor?
Você já deve ter visto falar da Alexa, assistente virtual da Amazon. Seu software foi criado com tecnologias de Deep Learning e aprende a cada nova interação que fazemos com ela por meio dos comandos de voz.
Basicamente, a complexidade do Deep Learning é bem maior, consistindo em um conjunto de algoritmos, capazes de modelar e processar altos níveis de abstração de dados através de grafos profundos e uma série de camadas de processamento, que realizam em tempo-real transformações lineares e não-lineares.... OK, mas o que isso significa em português? rsrs
São formas de Inteligência Artificial, que usam técnicas avançadas, com o objetivo de imitar a funções cognitiva de aprendizado do ser humano de maneira intuitiva. Como a Alexa, da Amazon.
Model Tuning
O Model Tuning é um processo que tem o objetivo de melhorar a escolha do hiperparâmetro mais preciso para um algoritmo utilizado no aprendizado de máquina.
Todo algoritmo possui diferentes hiperparâmetros e por meio do modelo tuning é possível dizer qual é o mais adequado para cada situação. Model Tuning é a prática onde se ajusta o modelo de Machine Learning criado, para alcançar maior acurácia na sua capacidade preditiva de prever corretamente o resultado. É onde vamos encontrar a melhor separação do dataset entre a divisão entre o que será a parte de treino, que irá alimentar o modelo e qual será a parte de teste, para testar a capacidade do modelo e da previsão.
Determinar qual conjunto de hiperparâmetros resulta no modelo mais preciso.
Esse processo é importante pois permite que você construa modelos personalizados que vão gerar resultados muito mais precisos e com isso fornecer insights mais ricos a respeito dos seus dados. Assim é possível fazer tomadas de decisão mais assertivas.
Afinal de contas. dentro de um mesmo dataset e um mesmo modelo de ML, você pode encontrar diferentes repartições e divisões, e também, diferentes taxas de acurácia de previsibilidade do modelo, sendo o Model Tuning um conjunto de práticas para encontrar os parâmetros ótimos para o melhor modelo possível, dentro de um determinado conjunto de dados.
Dicas práticas de como aprender Data Science do zero
Depois de tanta teoria e explicações, é hora de você ver dicas para praticar tudo aquilo que eu disse aqui.
Nos trechos a seguir eu também te mostro alguns sites para você aprender Python e Data Science sozinho. Veja a seguir!
Faça um projeto
Muitas das ferramentas que citamos aqui são gratuitas e você pode acessar de qualquer computador. Além disso, bancos de dados públicos são que não faltam para você brincar de fazer análise de dados e você pode usar uma das ferramentas que já citamos no texto, o Kaggle.
Você pode criar sua conta no Google Collab e explorar os recursos da ferramenta. O notebook Jupyter também é uma boa opção para essa tarefa.
Por serem duas ferramentas online você não precisará ter um super computador ou algo do tipo para explorar o universo da ciência de dados.
Leia Livros, Blogs e Conteúdos de Data Science
Para aproveitar o máximo de aprendizado possível é necessário ter uma total imersão no assunto para absorver o máximo de informações.
Ler livros sobre ciência de dados permite que você siga uma linha lógica de aprendizado com contextualização, desenvolvimento e conclusão de determinado assunto.
Como data science é uma área tão plural, você terá muitas opções para escolher, mas vou citar alguns dos principais:
Além disso, complemente sua leitura com conteúdos da internet. Minha recomendação é buscar fontes estrangeiras pois alguns mercados de tecnologia estão mais maduros que o brasieleiro e por isso você pode beber água direto da fonte.
Alguns que mais gosto são:
IBM Big Data & Analytics Hub;
Blog e podcast DataCamp;
Central Data Science;
KDnuggets;
Data Science
Participe de Comunidades
Outra forma de aprender data science é participar de comunidades sobre o assunto.
Existem muitas no Brasil e em todo mundo. As comunidades permitem que você compartilhe suas dúvidas e receba opiniões e ajuda de profissionais que estão num nível de conhecimento mais avançado que você.
Além disso, mesmo que você já domine bem o assunto, sempre acontece discussões de diferentes casos que acontecem no dia a dia do programador e quais atitudes o profissional teve para resolver o impasse.
Algumas comunidades interessantes que eu recomendo são:
Por mais que o aprendizado individual seja uma das opções mais fáceis e econômicas, esse tipo desenvolvimento pessoal não vai te fazer um cientista de dados.
Ele apenas vai permitir que você tenha uma base prática para iniciar sua carreira. Mas para te ajudar nessa empreitada inicial destacamos 2 sites principais:
Esse site possui um catálogo de cursos robusto para quem quer aprender data science. O mais interessante é que você pode explorar grande parte dos recursos de maneira gratuita.
Alunos que hoje fazem parte da equipe de gigantes da tecnologia como Facebook, Amazon e Uber já fizeram seus cursos:
Por ser uma plataforma totalmente focada em ciência de dados você poderá acessar cursos como:
Fundamentos de Python para Data Science;
Fundamentos de Pandas & Numpy;
Limpeza de dados e análises;
Como contar histórias através da visualização de dados;
Fundamentos de SQL;
Estatística intermediária;
Fundamentos da probabilidade;
Muito mais.
Além disso, você poderá participar da comunidade de alunos e interagir com eles.
É importante lembrar que os cursos são gravados no idioma inglês e é interessante que você tenha ao menos o nível básico da língua para aproveitar tudo que puder das aulas online.
Muito parecido com o site anterior, o datacamp também permitirá que você construa sua base de conhecimento por meio de videoaulas gratuitas ou pagas.
Eles apostam numa metodologia onde você vive um ciclo constante de aprender, praticar, aplicar, avaliar e aprender novamente…
O mais interessante é que a plataforma possui cursos que vão além da análise de dados aplicada apenas a programação e permite que o usuário explore finanças aplicadas ou análise de marketing.
Assim como a plataforma anterior você poderá participar de uma comunidade de estudantes da área e os cursos também são disponibilizados no idioma inglês.
O que é um bootcamp? Por que fazer um bootcamp de Ciência da Dados?
O bootcamp utiliza uma metodologia de ensino que incentiva o aluno a imergir nos assuntos trabalhados ao longo do curso que dura em torno de 9 semanas (para quem deseja se dedicar full time) ou 24 semanas (para quem deseja se dedicar part time).
Além de te dar toda a teoria para você começar a aprender data science, o bootcamp vai te proporcionar uma aprendizagem hands on, colocando a mão na massa e programando para resolver problemas de Data Science reais, desde o day 01. Lá você aprende o suficiente para sair com o nível de um Cientista de Dados Jr. no mercado.
A Le Wagon tem uma semana de carreiras, onde conectamos empresas de hiring partners para ajudar os recém formados de um bootcamp e a conseguirem seu primeiro emprego na área. Em média nossos alunos se aloca no mercado de trabalho em até 02 meses após de formado.
Após a finalização do bootcamp você é desafiado a construir um projeto completo e funcional. Sendo assim, você termina o curso com 02 projetos já prontos que contam para seu portfólio profissional.
Diferente de cursos online como Dataquest e Datacam, que são excelentes para aprender uma parte do processo específica, ou aprender introdução à programação que vão ser seus primeiros passos para ter um contato inicial com esse conteudo, no bootcamp o aprendizado é peer to peer, de ponta a ponta. Você sai com a formação completa de todos os conhecimentos precisos para ser um Data Scientist, um verdadeiro Cientista de Dados. E aí, depois de formado no bootcamp, cabe a você definir em qual área, uma vez que conheceu todas as etapas do processo de ciência de dados, você quer se especializar.
Imagine que Data Science é uma receita de bolo, com várias etapas e ingredientes. Cursos online vão te dar alguns ingredientes ou domínio de etapas específicas do processo, mas dificilmente você terá o domínio do processo completo para fazer um bolo de chocolate por completo. Já no bootcamp você aprende todas as etapas da receita do bolo e aprende a fazer o bolo sozinho. Sacou a diferença? A Le Wagon é seu golden ticket para o mercado de trabalho. Os cursos online são as etapas preliminares que vão te preparar melhor para o bootcamp. Ambos são fundamentais e complementares.
Se você ficou interessado em aprender data science num bootcamp, a Le Wagon está com vagas abertas para sua próxima turma.
Conheça os módulos do bootcamp de Data Science da Le Wagon: Aprender Data Science do Zero: Bootcamp de Ciência de Dados da Le Wagon Temos unidades em diferentes cidades do Brasil e você tem a possibilidade de escolher a que estiver mais perto de você.
Clique aqui, faça sua inscrição e dê o passo inicial para se tornar um profissional de ciência de dados que será cobiçado no mercado.